Образец цитирования
Соловьев С.Ю., Стельмашенко Д.Е.
Применение принципов экспертной классификации
для анализа формальных понятий
// Бизнес-информатика.
– 2013. – No.4(26). – C. 53-57
В статье рассматривается вариант задачи конструирования
решетки формальных понятий и обсуждаются особенности
алгоритма ее решения. Для повышения эффективности алгоритма
предлагается использовать принципы экспертной классификации.
1. Введение
В последнее время анализ формальных понятий
(англ. Formal Concept Analysis; FCA) выступает
своеобразным собирателем различных методов
обработки неколичественных данных. В работе
рассматривается вопрос о применении основных
принципов экспертной классификации для одной
задачи анализа формальных понятий. Систематическому
изложению этих родственных направлений искусственного
интеллекта посвящены монографии [1-4], здесь же
приводится минимально необходимый набор сведений
из FCA (п. 2), а также адаптированные под конкретную
задачу (п. 3) основы экспертной классификации (п. 4).
Результатом такого "симбиоза" стали новые подходы к
обработке формальных понятий (п. 5) и формулировки
новых задач.
2. Некоторые определения FCA
Формальный контекст есть тройка множеств
( G, M, I),
в которой элементы G называются объектами,
элементы M - признаками,
а I есть подмножество
из G × M.
Если ( g, m) ∈ I,
то говорят "объект g обладает признаком m"
либо, что тоже самое, "признак m встречается в
описании объекта g". При переходе от традиционных
неколичественных моделей проблемных областей (первичных моделей) к формальным контекстам (вторичным моделям)
каждый атрибут-свойство X с конечным числом значений
X1, ..., Xn
кодируется набором (0,1)-признаков
по принципу "одно значение атрибута –
один признак контекста".
Формальный контекст
K = ( G, M, I)
порождает так называемые формальные понятия.
Пара непустых подмножеств ( A, B),
где A ⊆ G
и B ⊆ M,
называется формальным понятием, если
(1) каждый объект из A обладает
всеми признаками из B, и
(2) никакая другая
пара ( A ∪ A ′, B ∪ B ′)
не удовлетворяет требованию (1).
Пары множеств (∅, M) и ( G,∅)
являются формальными понятиями по определению.
Если ( A, B) – формальное понятие контекста
K, то
A называется объемом понятия,
B – его содержанием.
В дальнейшем изложении будем полагать,
что множества G и M конечны,
а все термины "контекст", "понятие" и "содержание"
автоматически подразумевают спецификацию "формальный".
Множество C( K) всех понятий контекста
K образует полную решетку, с отношением
частичного порядка
(A1,B1) « (A2,B2) ⇔ B1 ⊇ B2
Соответственно, решеткой также является множество
S( K) = { B | ( A, B) ∈ C( K) }
с отношением частичного порядка ⊇.
Решетки C( K) и S( K) изоморфны;
располагая одной из них, можно построить другую решетку.
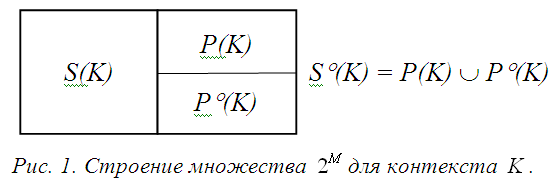
Рассмотрим подробнее те наборы признаков,
которые не относятся к S( K) и образуют
множество So( K) = 2 M \ S( K).
Подмножество признаков H контекста
K = ( G, M, I)
будем называть запретом, если
H ≠ M
и в описаниях объектов признаки из H
вместе никогда не встречаются:
∀ g ∈ G
∃ b ∈ H :
(g,b) ∉ I.
Требование H ≠ M
объясняется лишь тем, что в содержаниях понятий
– элементах множества S( K) –
все признаки запретов
встречаются исключительно в понятии (∅, M).
Множество всех запретов контекста K
обозначим P( K).
Кроме того, обозначим Po( K)
множество So( K) \ P( K).
Описанная классификация всевозможных наборов признаков представлена на рисунке 1.
Эквивалентным представлением контекста
K = ( G, M, I)
является объектно-признаковая таблица Tab( K),
в которой именами столбцов служат признаки из M,
кодами строк – объекты из G,
а на пересечении строки g и столбца m
стоит [×],
если ( g, m) ∈ I.
Общее определение контекста допускает наличие в нем
объектов-дубликатов, которым в Tab( K)
соответствуют строки, отличающихся только кодами.
Объекты-дубликаты не влияют на структуру решетки
понятий, поэтому для многих приложений интерес
представляют контексты без объектов-дубликатов,
именуемые далее простыми контекстами. Не ограничивая общности,
можно полагать, что в простом
контексте ( G, M, I)
каждый объект g из G
представляет собой подмножество признаков, а
I = φ(G) ≡ {(g,m) | g ∈ G, m ∈ g }.
При таком подходе для задания простого контекста
достаточно перечислить описания его объектов.
3. Задача совмещения формальных контекстов
Очевидно, что любой нетривиальный контекст K
способен порождать некоторые производные контексты
посредством вычеркивания из Tab(K)
отдельных строк-объектов и/или столбцов-признаков.
На содержательном уровне задача совмещения контекстов
состоит в конструировании решетки C(K)
неизвестного контекста K по производным от него
контекстам
K1 = (G1,
M1,
I1 )
и
K2 = (G2,
M2,
I2 ).
Известные подходы к решению задачи совмещения различаются
дополнительными предположениями и целевыми установками.
Для контекстов общего вида в случае
G1 = G2 = G,
M1 ∪ M2 = M
и
M1 ∩ M2 = ∅
задача совмещения контекстов часто решается посредством
так называемой "Nested Line" диаграммы [1]. Построение
"Nested Line" диаграммы предполагает подстановку диаграммы
Хассе решетки C(K1)
в каждый узел соответствующей диаграммы
решетки C(K2).
Считается, что построенная таким образом диаграмма
более наглядна, чем диаграмма Хассе решетки C(K).
Для контекстов общего вида в случае
G1 ∪ G2 = G
и
M1 ∪ M2 = M
искомую решетку C(K)
предлагается [5] строить по контексту
K = (G1 ∪ G2,
M1 ∪ M2,
I1 ∪ I2 ).
Метод используется для пополнения баз знаний.
Модификация метода [6] позволяет выявить в
объединенном множестве признаков дубликаты
и модифицировать отношение
I1 ∪ I2.
Упомянутые подходы к решению задачи совмещения не претендуют
на точное построение решетки C(K).
Иначе устроен метод @FC [7,8], о котором речь пойдет далее.
Название метода происходит от первых букв ключевых слов его
описания: Alternative design, Testing, Formal context, Concept.
Метод @FC использует специальную терминологию простых контекстов.
Если
K = (G, M, φ(G))
– простой контекст, заданный множеством своих объектов
G (глобальный контекст), то проекцию G
на фиксированное подмножество признаков MT
будем называть локальным контекстом.
Формально, локальный контекст KT есть
K = (GT, MT, φ(GT)),
где
GT = { g ∩ MT | g ∈ G }.
На практике получение KT
может быть связано, например, со снаряжением целой
экспедиции к местам обитания изучаемых объектов G,
причем исследовательские возможности экспедиции
ограничены набором признаков MT.
Для глобального контекста K
и пары локальных контекстов
K1,
K2
в случае
M1 ∪ M2 = M
метод @FC предлагает строить
множество S(K) в виде
{ B1 ∪ B2 | B1 ∈ S(K),
B2 ∈ S(K) }
с последующей пошаговой классификацией элементов V
на элементы S(K) и So(K).
Доказано, что метод @FC позволяет построить
множество S(K) за конечное число шагов.
На каждом шаге построения принимается решение о запросе
нового локального контекста, и по итогам его специальной
обработки для некоторых элементов V
принимаются классификационные решения. Процесс формирования
S(K) заканчивается, когда классификационные
решения приняты для всех элементов множества V.
Запрос нового локального контекста в виде множества его
признаков MT
формируется автоматически или в диалоге с пользователем.
При этом варианты запросов известны заранее, и необходимо
"лишь" выбрать лучший из них.
В части обработки локальных контекстов KT
метод @FC использует правила классификации, которые иногда
позволяют относить элементы V
к классам S(K)
или So(K).
Приведем в качестве примера два классификационных правила:
(K1) Если v ∈ S(KT)
и
{ v ′ | v ∪ v ′ ∈ V } = { ∅ },
то v ∈ S(K).
(K2) Если v ∈ P(KT)
и
v ∪ v ′ ∈ V
для некоторого v ′,
то
v ∪ v ′ ∈ P(K).
С одной стороны, классификационные правила
представляют собой строго доказанные утверждения [8],
а с другой стороны - их можно использовать в качестве
условных операторов алгоритма реализации метода @FC.
Обработка очередного локального контекста заканчивается,
когда все правила классификации оказываются неприменимыми.
При высокой стоимости локальных контекстов возникает
потребность в технологиях их "глубокой переработки",
позволяющих на каждом шаге классифицировать как можно
больше элементов V. Аналогичная потребность
исследовалась в 1980-х научным коллективом под
руководством О.И.Ларичева. Результатом этой работы
стал метод экспертной классификации, позволяющий при
незначительных дополнительных, но проверяемых
предположениях существенно увеличить количество
классификационных решений в задаче совмещения
формальных контекстов.
4. Принципы экспертной классификации
В терминах FCA главная идея метода экспертной
классификации состоит в обоснованном переносе
классификационных решений, полученных для одного
объекта, на некоторые другие объекты. Базой
знаний для обоснования и переноса служит отношение
доминирования, которое, в свою очередь,
строится из отношений характерности. Считается, что
контекст
K = (G, M, I)
представляет собой вторичную модель проблемной
области, а в первичной модели используются
атрибуты-свойства, принимающие конечное число значений.
При этом контекст K наследует от первичной модели
разбиение множества признаков
M = M1 ∪
M2 ∪
... ∪
Mk,
в котором каждое подмножество Mi
соответствует ровно одному атрибуту.
Теоретическую основу метода экспертной классификации
составляет гипотеза, согласно которой "признаки каждого
множества Mi различаются по
степени характерности для объектов G". Если для
конкретной проблемной области гипотеза справедлива, то
эксперт способен построить на элементах множества
Mi
асимметричное, антирефлексивное
и транзитивное отношение характерности <i;
запись
"mi1 <i
mi2"
означает, что признак mi1
менее характерен для объектов G,
чем признак mi2.
Экспериментально установлено, что фраза
"быть характерным для объектов G" и фразы,
производные от нее, понятны эксперту без разъяснений,
и он почти всегда способен построить k
штук отношений характерности – по одному
для каждого множества Mi.
Строго говоря, в оригинальном описании экспертной
классификации предполагается линейность всех отношений
характерности. Это обстоятельство существенно для
представления данных и для организации диалога
с экспертом при извлечения знаний об отношениях
характерности. В настоящей работе вместо линейного
порядка предполагается наличие частичного порядка.
Соответственно, изменяется процедура опроса эксперта,
в основу которой полагается сравнение на характерность
в различных парах признаков из Mi.
Совокупность отношений характерности
<1, ..., <k
порождает рефлексивное, антисимметричное
и транзитивное отношение доминирования ≤
на всевозможных подмножествах признаков из M.
По определению, пара подмножеств b1
и b2 связана отношением
b1 ≤ b1,
если для любого i = 1, ..., k
выполняется одно из двух:
–
либо
b1 ∩ Mi
= b2 ∩ Mi,
–
либо
b1 ∩ Mi
= { mi1 },
b2 ∩ Mi
= { mi2 } и
mi1 <i
mi2.
Если отношение доминирования удается построить,
то механизм переноса классификационных решений
применительно к объектам контекста
– элементам множества G –
описывается двумя постулированными,
но вполне разумными правилами:
(П1)
Если g1 ∈ G,
g ∈ 2M и
g1 ≤ g,
то g ∈ G;
(П2)
Если g1 ∉ G,
g ∈ 2M и
g ≤ g1,
то g ∉ G.
5. Метод доминирования для формальных контекстов
Метод @FC, в отличие от оригинальной версии экспертной
классификации, оперирует не только описаниями объектов,
но и другими подмножествами признаков. В связи с этим
возникает необходимость корректного обобщения правил П1
и П2 на случай подмножеств из V, и главная роль
в таком обобщении отводится формальной интерпретации
отношения характерности.
Простейшая, хотя и не единственная теоретико-множествеая
интерпретация отношений <i
имеет вид:
mi1 <i
mi2
⇔
{ g ∈ G | mi1 ∈ g }
⊆
{ g ∈ G | mi2 ∈ g } .
Доказано, что при таком подходе к отношениям характерности правила П1 и П2 превращаются в формальные утверждения, а кроме того, справедливы также утверждения
(П3)
Если v1 ∈ S(K),
v ∈ V и
v1 ≤ v, то
v ∈ S(K);
(П4)
Если v1 ∈ So(K),
v ∈ V и
v ≤ v1, то
v ∈ So(K);
(П5)
Если v1 ∈ P(K),
v ∈ V и
v ≤ v1, то
v ∈ P(K);
(П6)
Если v1 ∈ Po(K),
v ∈ V и
v ≤ v1, то
v ∈ Po(K).
В доказательствах утверждений П3-П6 существенно
используются свойства объектов глобального контекста,
однако в окончательных формулировках объекты
не фигурируют, что позволяет использовать утверждения
П3-П6 в качестве дополнительных правил распространения
классификационных решений метода @FC.
6. Заключение
Представленная модификация метода совмещения @FC применима
для глобальных контекстов, удовлетворяющих гипотезе
доминирования в ее простейшей интерпретации. Проверка гипотезы
по решетке содержаний представляет собой самостоятельную
теоретическую задачу, способную в перспективе породить новую
версию алгоритма совмещения локальных контекстов. Кроме того,
один из принципов экспертной классификации состоит в
обязательном исследовании наборов признаков на границах
классов, адаптация этого принципа для задач FCA также
представляется весьма перспективной.
Предложенный и намеченные алгоритмы могут использоваться
при решении практических задач бизнес-информатики,
сводимых к обработке формальных понятий.
Литература
- Ganter B., Wille R. Formal Concept Analysis: Mathematical Foundations. - Springer, 1999.
- Гуров С.И. Булевы алгебры, упорядоченные множества, решетки: Определения, свойства, примеры. - М.: ЛИБРОКОМ, 2013.
- Ларичев О.И. Теория и методы принятия решений, а также Хроника событий в Волшебных Странах. - М.: Логос, 2000.
- Ларичев О.И., Мечитов А.И., Мошкович E.M., Фуремс Е.М. Выявление экспертных знаний. - М.: Наука, 1989.
- Li G.Y., Liu S.P., Zhao Y. Formal Concept Analysis based Ontology Merging Method // Proceeding of 3rd IEEE International Conference on Computer Science and Information Technology. - 2010 - volume 8 - P. 279-282.
- Bendaoud R., Napoli A., Toussaint Y. A proposal for an Interactive Ontology Design Process based on Formal Concept Analysis // Frontiers in Artificial Intelligence and Applications. - 2008 - volume 183: Formal Ontology in Information Systems - P. 311-323.
- Стельмашенко Д.Е. Алгоритм восстановления глобального контекста // Сборник статей молодых ученых факультета ВМК МГУ. - 2012 - выпуск 9 - C.191-209.
- Соловьев С.Ю., Стельмашенко Д.Е.
Подходы к исследованию формальных контекстов
// Информационные процессы. - 2011 - том 11 - № 2
- С. 277-290.
www.park.glossary.ru/serios/read_14.php
APPLICATION OF THE EXPERT CLASSIFICATION PRINCIPLES
FOR FORMAL CONCEPT ANALYSIS
Stelmashenko Daria Evgenyevna,
Lomonosov Moscow State University, Russia, Moscow,
Soloviev Sergey Yurievich,
Lomonosov Moscow State University, Russia, Moscow.
ABSTRACT:
The article is devoted to the problem of merging local
contexts that in the terms of different sets of attributes
describe the same global set of objects. The resulting
solution of this problem is a formal concept lattice that
is defined on a global set of objects via the unified set
of attributes. Among the known methods for solving this
problem the @FC method is chosen, which allows to precisely
build the desired lattice. It is marked that the @FC
method brings the solution of the problem to a sequence
of formally-grounded classification solutions, referred
to the partially given descriptions of objects.
The complexity of solving the problem with @FC method
is in the direct dependence from the number of successful
classification decisions, which brings in the necessity
of expanding their range. In analogous conditions
an expert classification method performed as a rather
effective instrument that allows to transfer the once
obtained classification decisions on other objects.
The base of the expert classification method is formed
by the domination relation on objects descriptions,
which is obtained during the dialog with an expert.
The fundamental difficulty in incorporating of expert
classification method into the @FC method is in the
necessity of a self-consistent extrapolation of the
domination relation on partial descriptions of objects
from the global set. The article describes a concrete
method for extrapolation of the domination relation,
which eliminates this difficulty and allows combining
of these two methods. The immediate practical result
of this research is the development of an effective
modification of the context merging method. From the
theoretical point of view the proposed way of combining
the two methods generates a number of interesting
research topics.
Key words: formal concept analysis,
expert classification method,
principle of domination by specificity,
specificity scale.
|